
Unlocking the Power of PDF with Open AI: A Guide to Building Your Own Q&A System


Table of contents
Introduction
Natural Language Processing (NLP) is an exciting and rapidly-evolving field of Artificial Intelligence that aims to enable computers to understand, interpret, and generate human language. Reading and extracting information from PDF files is a crucial task in various industries, from healthcare to legal to education. However, manually searching through lengthy documents to find specific information can be a time-consuming and tedious process. In recent years, QA systems have made impressive strides thanks to advancements in deep learning and large-scale language models, such as OpenAI's GPT-3.
In this blog, we will explore how to build a simple but effective Question Answering system using Python, Gradio, and GPT-3. Our system will be based on a Retrieval QA architecture, where candidate answers are first retrieved from a large corpus of documents using a similarity-based search algorithm, and then scored and ranked using a fine-tuned GPT-3 model. We will see how to integrate the Langchain library, a high-level Python interface to GPT-3, with Gradio, a user-friendly platform for building custom web interfaces for machine learning models, to create a user-friendly and interactive QA system. Finally, we will showcase our QA system in action by answering a range of questions on different topics, and discuss some of the challenges and limitations of QA systems based on large language models.
Block-by-block explanation of the code:
import gradio as gr
import os
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
This block imports the necessary libraries for the code to run, including Gradio for creating the user interface, and langchain for natural language processing tasks such as question answering.
def Question_answering(pdf_file, openai_key, prompt, chain_type, k):
os.environ["OPENAI_API_KEY"] = openai_key
# load document
loader = PyPDFLoader(pdf_file.name)
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(search_type="similarity", search_kwargs={"k": k})
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(), chain_type=chain_type, retriever=retriever, return_source_documents=True)
# get the result
result = qa({"query": prompt})
return result['result'], [doc.page_content for doc in result["source_documents"]]
This block defines a function qa_system that takes in five inputs: the PDF file to be processed, the OpenAI API key for language modeling, the question prompt, the type of chain to use for answering the question, and the number of relevant chunks to use for the answer. The function then performs the following tasks:
Load the PDF document using PyPDFLoader and split it into chunks of 1000 characters each.
Select which embeddings to use for the vectorstore.
Create the vectorstore using Chroma, which indexes the chunks using their embeddings.
Expose the vectorstore through a retriever interface, which returns the most similar chunks to the query.
Create a question-answering chain using the RetrievalQA class from langchain, which uses OpenAI's language model to answer the question.
Pass the query to the question answering chain and return the result along with the relevant source documents.
relevant source documents.
# define the Gradio interface
input_file = gr.inputs.File(label="PDF File")
openai_key = gr.inputs.Textbox(label="OpenAI API Key")
prompt = gr.inputs.Textbox(label="Question Prompt")
chain_type = gr.inputs.Radio(['stuff', 'map_reduce', "refine", "map_rerank"], label="Chain Type")
k = gr.inputs.Slider(minimum=1, maximum=5, default=1, label="Number of Relevant Chunks")
output_text = gr.outputs.Textbox(label="Answer")
output_docs = gr.outputs.Textbox(label="Relevant Source Text")
gr.Interface(Question_answering, inputs=[input_file, openai_key, prompt, chain_type, k], outputs=[output_text, output_docs],
title="Question Answering with PDF File and OpenAI",
description="Upload a PDF file, enter your OpenAI API key, type a question prompt, select a chain type, and choose the number of relevant chunks to use for the answer.").launch(debug = True)
Next, the code defines the input and output parameters for the Gradio interface, which allows the user to interact with the question answering system.
The input_file variable is defined as a gradio.inputs.File object, which allows the user to upload a PDF file. The openai_key variable is defined as a gradio.inputs.Textbox object, which allows the user to input their OpenAI API key. The prompt variable is defined as a gradio.inputs.Textbox object, which allows the user to input the question prompt. The chain_type variable is defined as a gradio.inputs.Radio object, which allows the user to select the type of chain to use for answering the question. Finally, the k variable is defined as a gradio.inputs.Slider object, which allows the user to select the number of relevant chunks to use for the answer.
The output_text variable is defined as a gradio.outputs.Textbox object, which displays the answer to the question. The output_docs variable is defined as a gradio.outputs.Textbox object, which displays the relevant source text for the answer.
Finally, the gr.Interface function is called to create the Gradio interface. The function takes in the qa_system function as the main function to run, and the input and output parameters defined earlier. It also includes a title and description parameter to provide a title and description for the interface. The launch method is called on the interface object to start the interface, with the optional debug parameter set to True to enable debugging mode.
Demo:
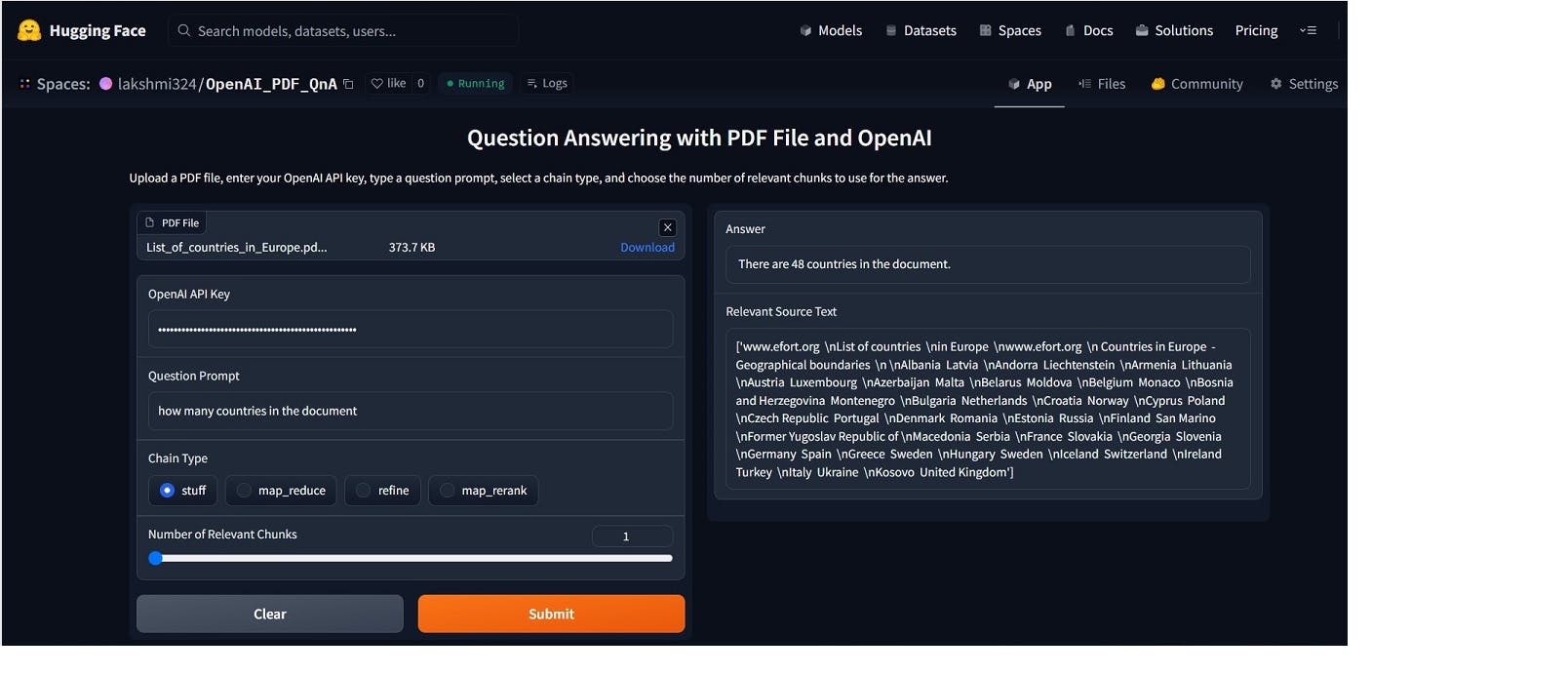
Conclusion
In conclusion, we have demonstrated how to build a powerful Question Answering system using the LangChain library and Gradio. By leveraging cutting-edge techniques in natural language processing, such as document embedding and retrieval-based QA, we were able to create an application that can effectively answer questions posed in natural language using a PDF document. The integration of OpenAI's powerful GPT-3 language model also adds an additional layer of accuracy and sophistication to the system. Overall, this project showcases the immense potential of NLP in unlocking new capabilities for computer systems to interpret and generate human language, and opens up exciting possibilities for future applications. With further advancements in AI and NLP, the possibilities for creating more sophisticated and accurate QA systems are endless, and we can expect to see even more exciting developments in this field in the years to come.